

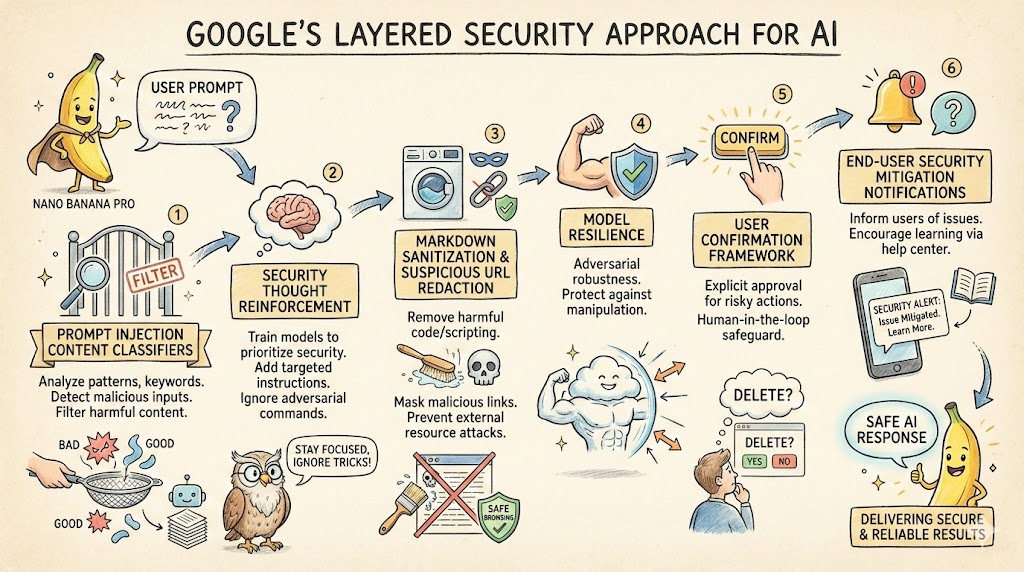
Prompt injection content classifiers—Proprietary machine-learning models that detect malicious prompts and instructions within various data formats. Security thought reinforcement—Targeted security instructions that are added around the prompt content. These instructions remind the LLM (large language model) to perform the user-directed task and ignore adversarial instructions. Markdown sanitization and suspicious URL redaction—Identifying and redacting external image URLs and suspicious links using Google Safe Browsing to prevent URL-based attacks and data exfiltration. User confirmation framework—A contextual system that requires explicit user confirmation for potentially risky operations, such as deleting calendar events. End-user security mitigation notifications—Contextual information provided to users when security issues are detected and mitigated. These notifications encourage users to learn more via dedicated help center articles. Model resilience—The adversarial robustness of Gemini models, which protects them from explicit malicious manipulation.



0 Comments
👥 Co-learning Circle 0
Observe other members' variables & configurations, and click "Study & Retry" to instantly import settings and practice!